
What is Web Scraping?
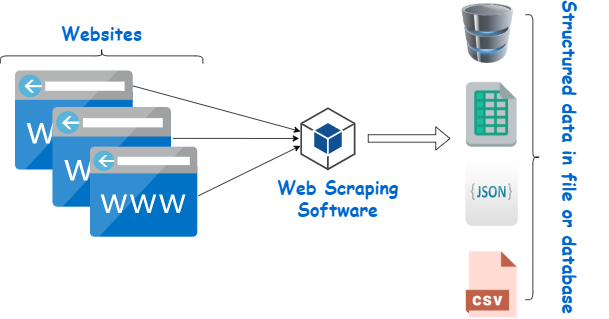
Web scraping is the process of extracting data from websites, either manually or using software. It is a technique used in data mining and data analytics to collect data from various sources, including social media platforms, e-commerce platforms, forums, and news websites. The process involves retrieving web pages and analyzing their content, which can include text, images, and other multimedia.
Web scraping is used in many industries, including finance, marketing, and e-commerce. It is often used to gather information on competitors, monitor trends, and create customized marketing campaigns. The data collected can be analyzed to identify patterns, generate insights, and inform business decisions.
Web scraping can be done manually, but more often it is done using automated tools called web scrapers. These tools use web crawlers to access different parts of a website and extract data. Web scrapers can be programmed to collect a variety of data, such as product information, customer reviews, social media interactions, and market trends.
There are various web scraping techniques, including screen scraping, HTML parsing, and DOM parsing. Screen scraping involves capturing the visible content on a webpage, while HTML parsing involves extracting data from HTML code. DOM parsing involves analyzing the Document Object Model (DOM), a representation of a webpage.
Web scraping has many potential benefits, but there are also ethical and legal considerations to keep in mind. If done improperly, web scraping can violate the privacy and intellectual property rights of website owners. Therefore, it is important to ensure that web scraping is conducted in a responsible and ethical manner.




